Index Explains: TV en streaming
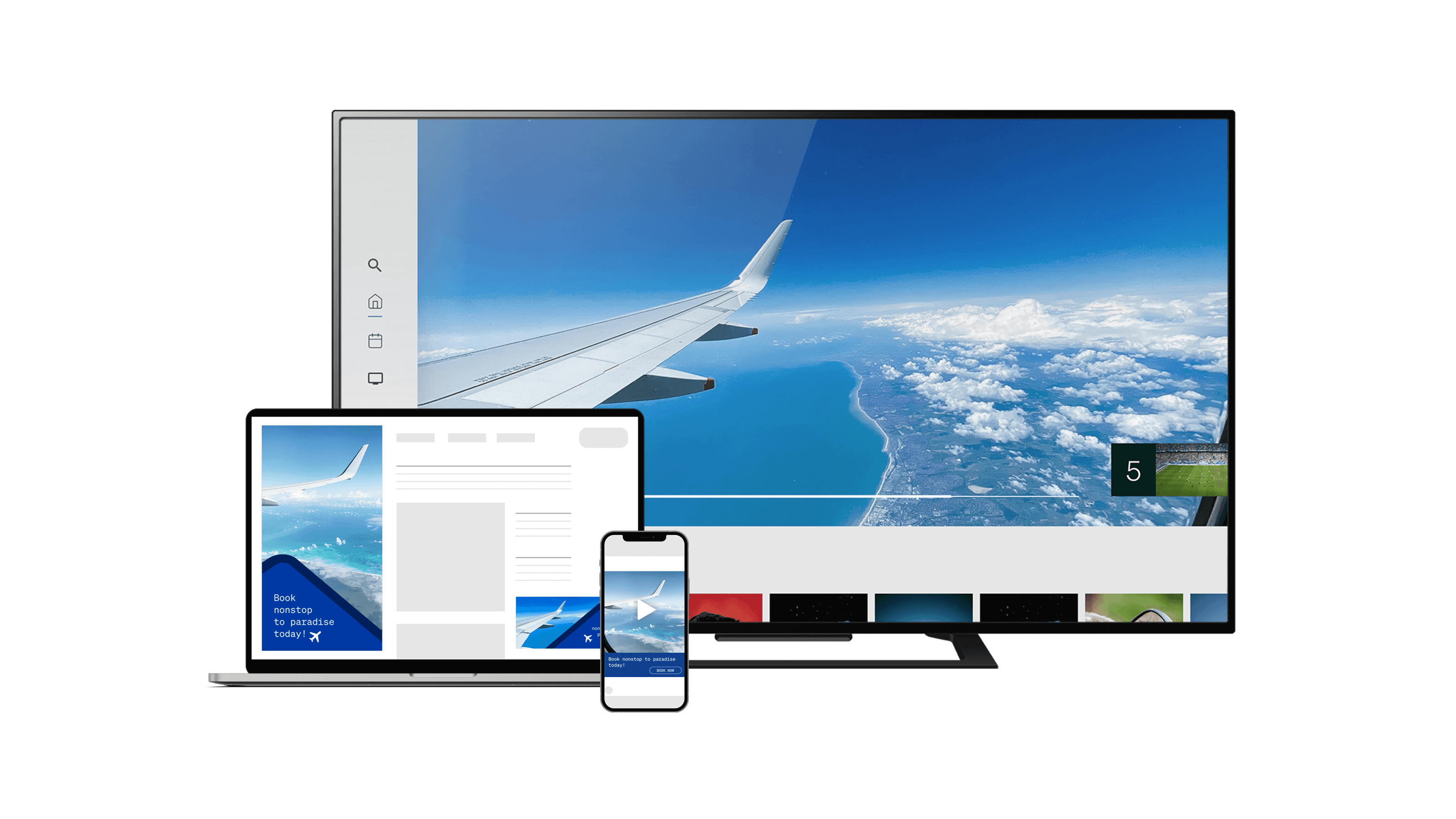
La publicidad en vídeo es sofisticada, pero no tiene por qué ser confusa. Sintonice nuestra nueva serie de vídeos en la que desmenuzamos todas las complejidades de la TV en streaming.
Ver ahoraComprende el verdadero valor de la TV en streaming a través de nuestro marketplace dinámico, diseñado para una entrega precisa y un rendimiento máximo.



La publicidad en vídeo es sofisticada, pero no tiene por qué ser confusa. Sintonice nuestra nueva serie de vídeos en la que desmenuzamos todas las complejidades de la TV en streaming.
Ver ahora
Nuestro ad exchange permite que propietarios de medios consigan mayores ingresos y que profesionales del marketing lleguen a consumidores con cualquier formato de anuncio.

Nuestra vocación es crear un marketplace omnicanal seguro y transparente que ofrezca a consumidores finales una experiencia en la que puedan confiar.

En nuestra nueva serie de blogs “Behind the Tech”, profundizamos en las mentes de los miembros de nuestro equipo de …
Leer más
A medida que trabajamos con más editores para comenzar a implementar y probar nuevas soluciones de Google Privacy Sandbox, en …
Leer más
Cuando se lanzó el protocolo OpenRTB 2.6 a principios de 2022, ofreció una serie de nuevas funciones que prometían revolucionar …
Leer másPonte en contacto con nuestro equipo para comprobar todo lo que podemos hacer por ti.
Contacto